In 2011, I wrote about the growing trend of moving applications to the cloud and some of the security issues that arise when we entrust cloud providers with our sensitive and critical data. Here is a link to that article: Client-Side Encryption for HTML Form Fields. While hacking by unauthorized third parties is generally seen as the primary risk in cloud applications and data, the specific concern I addressed was the privacy issues arising from the ability of service provider to view all the data submitted. Since then, data privacy issues have gained much greater visibility, especially in light of recent privacy concerns with data handling at Facebook (https://techcrunch.com/2018/04/10/a-brief-history-of-facebooks-privacy-hostility-ahead-of-zuckerbergs-testimony/).
At the time I wrote that article, the primary concern was hacking by unauthorized third parties. This is still a concern, and in many ways has gotten worse since them. But the problem of privacy due to the ability of the service provider to view all data submitted, has become an equally great concern, especially in light of events concerning Facebook (https://techcrunch.com/2018/04/10/a-brief-history-of-facebooks-privacy-hostility-ahead-of-zuckerbergs-testimony/).
Until recently, Gmail was reading the content of your email to better serve you targeted ads. They still read your email but claim not to do so for advertising purposes (https://variety.com/2017/digital/news/google-gmail-ads-emails-1202477321/). The previously mentioned Facebook incident illustrates how service providers share your information with third parties though we think it will only be available to those we authorize such as friends and family.
The root cause of the privacy concerns just mentioned is that this data is not hidden from cloud providers. To solve this problem, data must be encrypted before submission.
In my 2011 paper, I proposed client-side encryption as a standard component of HTML, implemented in the browser. That idea has not gained traction as far as I know. Ever since, I have been thinking of incorporating this technique into my own applications and have recently released a personal information manager that includes this feature.
Infoblazer Notes is an application similar to Evernote and Microsoft’s OneNote, or more so to Ecco Pro (for those who remember that one). All data is encrypted before being transmitted to the server with an encryption key know only to the user. I released an public Alpha version recently and plan to move to Beta very soon.
Here is an example comparing data submission of a quick note entered in Google Keep and Infoblazer Notes.
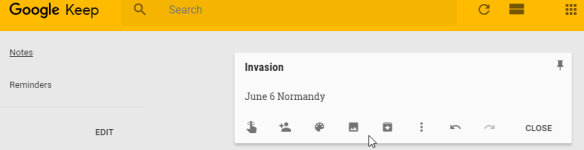
Here is what is submitted to Google Keep and what Google actually sees. Notice the critical information (highlighted) visible in clear text. Note that though the use of HTTPS/TLS encryption hides data during transmission, the receiver will see exactly what is shown below.

Here is what is sent to the Infoblazer Notes:

All information entered by the user is encrypted before submission. The only thing Infoblazer knows about the user is the email address used during registration. To further enhance privacy, the service doesn’t include targeted adds or incorporate other marketing. I also think the Infoblazer Notes outliner approach is much more functional than the commonly used Post-it note paradigm of Evernote et al.
Does this solution improve data privacy and is it feasible for widespread use? What do you think of my original proposal for client-side encryption in HTML? You can share your feedback on our Facebook page.