
In the last several posts, I used genetic programming (GP) to model time series by fitting an equation to observed data. The resultant equation was used to predict unseen data points. In this post, I discuss applying similar techniques to market investment decisions.
In their introductory textbook, Poli et al. list characteristics of problems that are well suited for GP. These characteristics are:
The interrelationships among the relevant variables is unknown or poorly understood (or where it is suspected that the current understanding may possibly be wrong).
Finding the size and shape of the ultimate solution is a major part of the problem.
Significant amounts of test data are available in computer-readable form.
There are good simulators to test the performance of tentative solutions to a problem, but poor methods to directly obtain good solutions.
Conventional mathematical analysis does not, or cannot, provide analytic solutions
An approximate solution is acceptable (or is the only result that is ever likely to be obtained)
Small improvements in performance are routinely measured (or easily measurable) and highly prized.
(Poli et al., 2008, pp.11-13)
Without much further explanation, it is evident to me that all these characteristics are apt descriptions of the problem of stock market prediction
Continuing with the equation fitting approach, we could attempt to model an equation describing a financial time series such as the S&P 500 Index. Assume we could determine an equation of the form
Today’s close = f (today’s date, historical prices)
that closely fits past price history. To apply this equation to investment decisions, we would need to determine the closing price for the following market date and decide whether to be invested or not for that day. To make predictions in this manner, we would need an almost omniscient knowledge of the exact path of the market. Achieving this aim is unlikely for many reasons, one being the large random factors influencing any day to day market move. To avoid the impact of day to day fluctuations, we might make predictions further out in the future, but how far? One option is to train the predictors using a criterion such as “will the target series gain X% in M days”, where X and M are user supplied values (Kampouridis & Tsang, 2010). While fitting an equation is a form of symbolic regression, this approach is a form of supervised learning. At any historical point, we know for certain whether an investment at that point would satisfy the target requirements of a specific future percentage gain, without the need to identify a specific equation. The resultant program would return a Boolean value instead of the numeric value used in our prior time series experiments.
An alternative GP approach looks at the broader question of whether to be in or out of the market at any point in time. Instead of a specific target return criterion, this approach simply asks, “find me the program that makes the most money” and evolves a program that yields the highest profit over the investment horizon. This is a form of unsupervised learning, as we are not providing the training algorithm the correct decision at any point in time.
In the following experiment, I will use GP to evolve a population of computer programs that return a Boolean (true or false) value determining whether to be fully invested or fully out of the market. The S&P 500 is used as the target investment. The evolutionary operations decide the applicable criteria for investment decision. Multiple fitness factors can be considered, such as the Sharpe ratio, maximum drawdown, etc., though this experiment will only look at investment return as the fitness criteria. This approach illustrates the flexibility of GP and is the approach is currently used in Evolutionary Signals.
Recall, GP evolves a population of computer programs over a set number of training generations to solve a targeted problem. After training, the best performing program is taken as the solution to the target problem. In this case, the best performing program will be use to make investment decisions.
Several training approaches are possible. These are:
- Train->Predict
- Train->Test->Predict
In the first approach, we run a fixed number of training generations on the GP population. At the end of the training phase, we use the best program for prediction. A problem with this approach is that the chosen prediction program may greatly overfit the training data and not be very applicable to out of sample data seen in ongoing prediction. Periodic retraining can somewhat ameliorate this issue.
A better training approach is to incorporate an out of sample testing phase. Again, we run GP for a set number of training generations. A new phase is added where the best performing program from the training phase is used to make predictions on a new set of test data. For time series, the test data needs to occur chronologically after the training data to avoid data snooping. GP runs this train-test cycle several times with the best program from each phase recorded. The best performing program over the set of testing phases is chosen for initial prediction. This approach takes more time to train, however.
In both approaches, training will generally continue during the ongoing prediction phase. Neither approach avoids the possibility that the training and testing periods are vastly different from data seen in the actual prediction periods. Again, periodic retraining, plus other techniques dealing with regime change, may help avoid this problem. Regime change approaches will be discussed on a future post. This issue is also addressed in my PhD dissertation.
While a nearly limitless number of predictor series are available, this experiment will use the S&P 500 daily close and volume history. Transaction costs will be ignored as will returns when out of the market. These are two factors traditionally used in technical analysis (as they were the only factors available back in the day, before company fundamental became widely available).
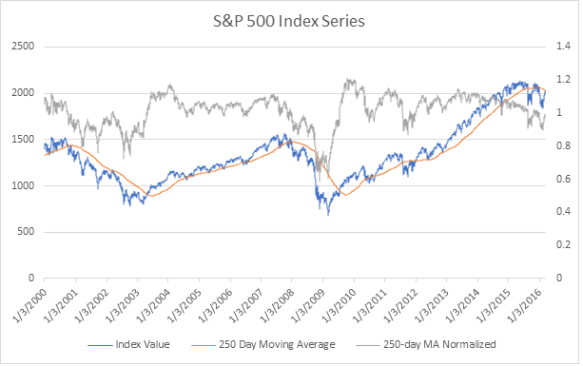
Most machine learning tasks require data to be normalized. Normalization smooths out discrepancies in scale within and between series. For example, comparing the units of S&P 500 price (thousands) to volume (billions) could greatly skew the results. In this experiment, I will apply mean normalization to both predictor series by dividing each price or volume value by the corresponding 250-day moving average. This operation transforms both series to a similar scale, fluctuating around 1. The following chart shows the target and normalized price series for the period considered in the experiment.
There are hundreds of technical indicators available (see Investopedia for a nice list) that could be incorporated into the GP algorithm, in addition to core the mathematical functions that were used in the prior time series experiments. This experiment will include several of the most common including:
- Momentum- compare the current value to a recent average (Ex. Buy if current price exceeds the 30-day moving average)
- Breakout- compare the current value to a recent minimum/maximum (Ex. Buy if current price risen by 2% over minimum price last 30 days)
There is a tradeoff between using high level packaged indicators, such as those listed on Investopedia, and lower level functions. Ideally, using lower level functions will discover new and novel indicators. Using higher level functions could yield better performance as these are technical indicators with known utility, but most of these are widely followed and it may be more difficult to act on signals in a timely manner.
The follow primitives will be used in the experiment:
| Functions | Terminals |
|---|---|
| Add Subtract Multiply Divide Gt Lt And Or Not OffsetValue IfElseBoolean MovingAverage PeriodMaximum PeriodMinimum AbsoluteDifference |
randomInteger(low=0, high=250) randomDouble(low=0, high=2) offsetValue(days=0) |
From this raw material, GP will evolve a population of programs (Boolean expressions) determining whether to invest or not at any point in time. A sample program we hope might evolve is:
(> (OffsetValue SP500 1) (MovingAverage SP500 30)
The expression states: invest if the prior day’s value of the S&P 500 index is above its 30-day moving average.
In the next post, I will provide the results of this prediction experiment.
References
Kampouridis, M., & Tsang, E. (2010). EDDIE for Investment Opportunities Forecasting: Extending the Search Space of the GP. In 2010 IEEE Conference on Evolutionary Computation (CEC) (pp. 1–8). IEEE.
Poli, R., Langdon, W. B., McPhee, N. F., & Koza, J. R. (2008). A field guide to genetic programming. Lulu. com.
